

Top 5 Advanced SQL Functions Every Data Professional Should Know


Hey Hustlers!
Most analysts get comfortable with basic SQL and stop there. GROUP BY, SUM, COUNT, maybe a LEFT JOIN here and there. But then you hit a wall where your queries get messy, take forever to run, or you end up writing the same logic over and over.
The functions I'm covering today aren't just nice-to-haves. They're the ones that separate junior analysts from senior ones. They make complex problems simple and turn 50-line queries into 10-line ones.
Let's dive into the five that'll actually change how you work with data.
1. ROW_NUMBER() OVER (PARTITION BY ... ORDER BY ...)
This one solves the "get the latest record for each customer" problem that haunts every analyst.
What it does: Assigns unique numbers to rows within groups, ordered however you want.
The old way (painful):

The better way:
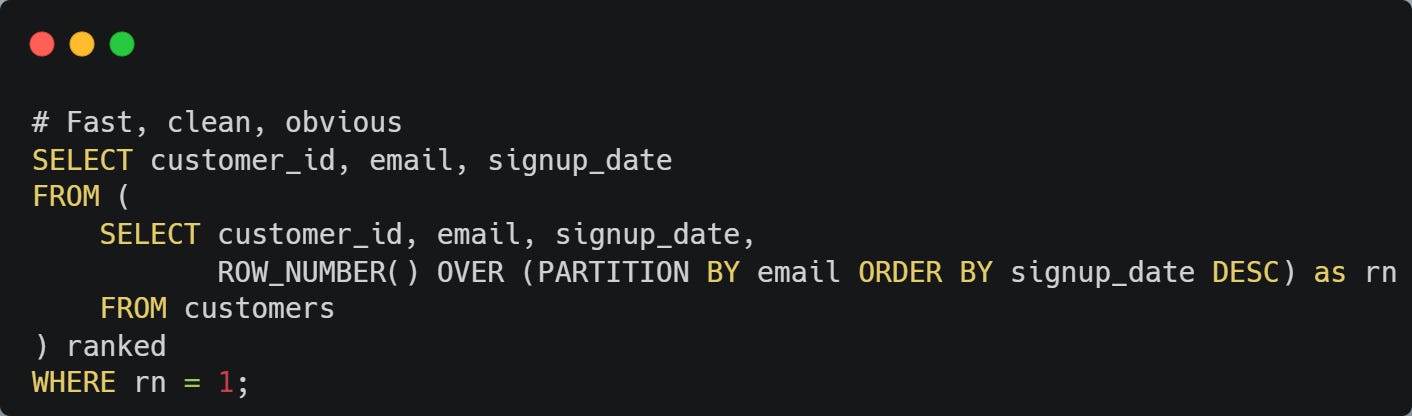
💡 Pro tip: ROW_NUMBER() is your go-to for deduplication. RANK() and DENSE_RANK() handle ties differently, but ROW_NUMBER() always gives you exactly one record per partition.
2. LAG() and LEAD()
These let you compare current rows with previous or next rows without crazy self-joins.
What they do: LAG() looks backward, LEAD() looks forward in your result set.
Perfect for: Month-over-month changes, detecting streaks, and finding gaps in data.
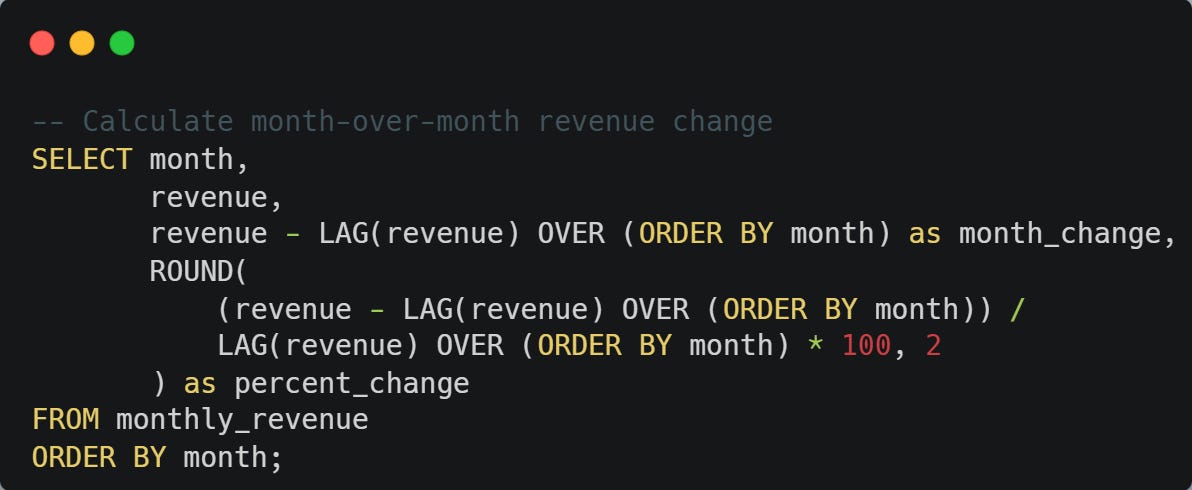
💡 Pro tip: Use LAG(column, 2) to look back two rows, or LAG(column, 1, 0) to default to 0 when there's no previous row.
If you're finding these insights helpful, Manisha (Data Science Lead at Google), Siddarth (Senior Director of Data Science at Microsoft), and I dive much deeper into real SQL and Python interview challenges in our weekend Coding Masterclass.
🎁 Just for our subscribers: We're offering 50% off for the next 48 hours, use code "THEDATAHUSTLE" at checkout.
3. CASE WHEN (beyond basic if-then)
Most people use CASE WHEN for simple true/false logic. But it's way more powerful than that.
Advanced use: Creating buckets, handling multiple conditions, and building pivot-like results.
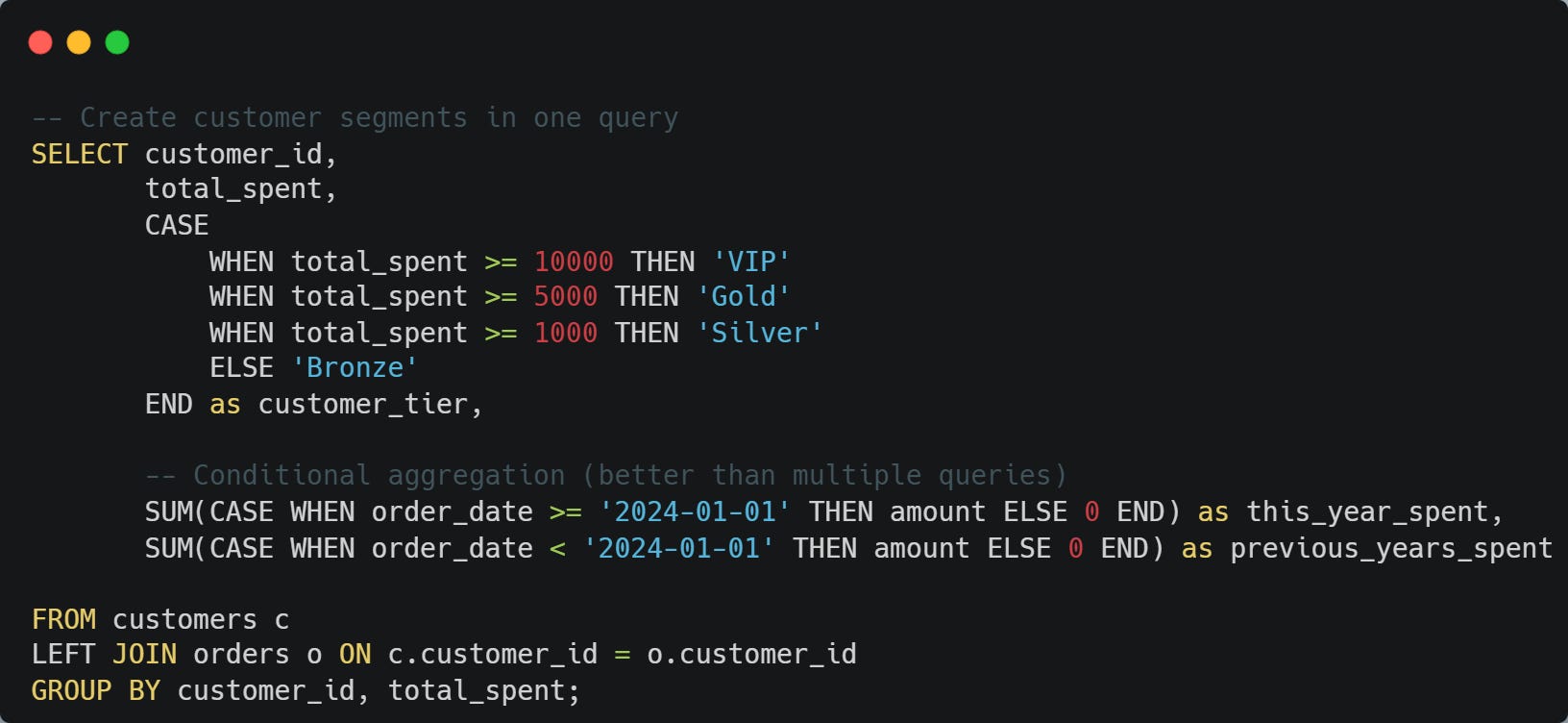
💡 Pro tip: CASE WHEN inside aggregations is incredibly powerful. Instead of multiple queries for different time periods, use conditional SUM/COUNT.
4. CTE (Common Table Expressions) - WITH clauses
CTEs make complex queries readable and let you reference the same subquery multiple times.
What they do: Create temporary, named result sets that exist only for your query.
Instead of nested subquery hell:
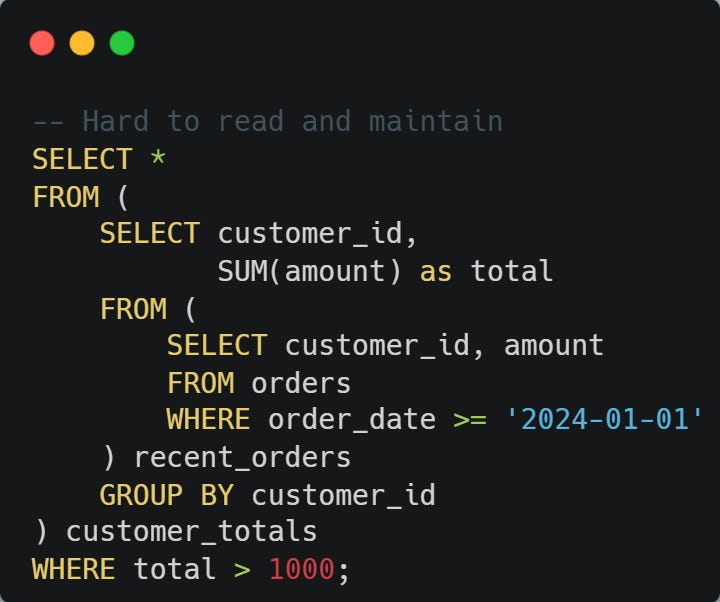
Use readable CTEs:
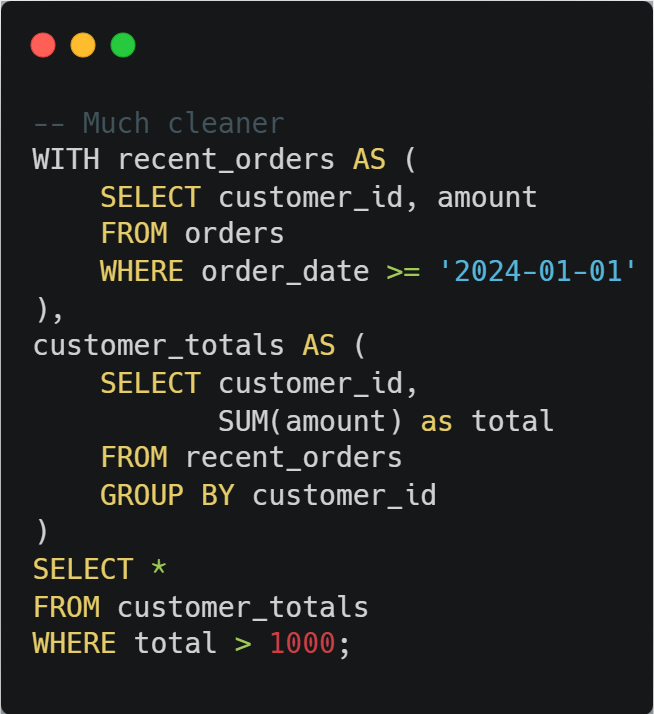
💡 Pro tip: CTEs are perfect for breaking down complex logic into digestible steps. Your future self (and coworkers) will thank you.
5. COALESCE() and NULLIF()
These handle NULL values way better than basic ISNULL or CASE statements.
COALESCE() returns the first non-NULL value from a list:
NULLIF() returns NULL if two values are equal (great for avoiding division by zero):

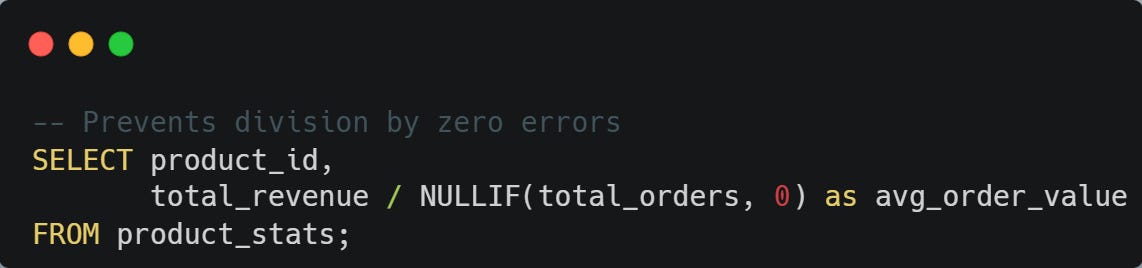
💡 Pro tip: COALESCE() is perfect for creating fallback hierarchies. NULLIF() saves you from error-prone division and comparison operations.
If you're finding these insights helpful, Manisha (Data Science Lead at Google), Siddarth (Senior Director of Data Science at Microsoft), and I dive much deeper into real SQL and Python interview challenges in our weekend Coding Masterclass.
🎁 Just for our subscribers: We're offering 50% off for the next 48 hours, use code "THEDATAHUSTLE" at checkout.
When to reach for these functions
ROW_NUMBER() - Anytime you need "the latest" or "top N per group"
LAG/LEAD - Comparing periods, calculating changes, detecting patterns
Advanced CASE WHEN - Creating segments, conditional aggregations, pivot-like logic
CTEs - When your query has more than two levels of nesting
COALESCE/NULLIF - Handling messy real-world data with grace
Stop writing harder queries than you need to
The analysts who stand out aren't the ones memorizing obscure functions. They're the ones who recognize patterns and know which tool fits each situation.
Key takeaways
ROW_NUMBER() eliminates messy subqueries for getting the latest/top records per group
LAG/LEAD makes time comparisons simple without complex self-joins
Advanced CASE WHEN creates segments and conditional aggregations in a single query
CTEs break complex logic into readable steps that you can build on
COALESCE/NULLIF handles real-world data messiness better than basic NULL checks
These aren't just fancy features to show off. They solve real problems you face every day as an analyst.
Which of these functions do you already use? And which one are you going to try this week? Hit reply and let me know!
Best of luck for everything!
- Sai Bysani, a fellow Hustler!
Keep grinding, keep growing,
The Data Hustle.
 | A guest post by
|